Tema: Improving TCP Congestion Control over Internets with Heterogeneous
Transmission Media
Christina Parsa and J.J. Garcia-Luna-Aceves
Computer Engineering Department
Baskin School of Engineering
University of California
Introducción
La "Transmisión de extremo a extremo de los datos fiables" es un servicio muy necesario para muchas de las aplicaciones actuales se ejecutan a través de Internet (por ejemplo, WWW, transferencia de archivos, correo electrónico, acceso remoto), que hace que TCP sea un componente esencial de la actual Internet.
Los problemas de rendimiento de las implementaciones TCP actuales de Internet en los medios de transmisión heterogéneos se derivan de las limitaciones inherentes en la recuperación de errores y mecanismos de control de congestión que utilizan.
El efecto secundario desafortunado de este enfoque es que no hay estimaciones y se realizan en períodos de congestión.
Dado que todos los métodos Reno y Tahoe no pueden realizar estimaciones de RTT durante períodos de congestión, una estrategia es la de un temporizador de retardo de envío donde se utiliza para evitar las retransmisiones prematuros.
Reno y Tahoe implementan TCP y muchas soluciones alternativas proponen el uso de pérdida de paquete como una indicación primaria de la congestión; un emisor TCP aumenta su tamaño de la ventana, hasta que se produzcan pérdidas de paquetes a lo largo de la ruta de acceso al receptor TCP.
Por otra parte, la fluctuación periódica y amplia de tamaño de la ventana típica de Reno y Tahoe provoca grandes fluctuaciones de retraso, por lo que la variación del retardo en los extremos de la conexión genera un efecto secundario que es inaceptable para aplicaciones sensibles al retardo.
Bajo tales condiciones, el control de la congestión sobre la base de acuse de recibo (ACK) contando como en TCP, Reno y Tahoe resultados en subutilización significativa de la mayor capacidad de enlace hacia delante debido a la pérdida de ACK en el enlace inverso más lenta.
Las pérdidas ACK también conducen al tráfico de datos muy explosivas en el camino hacia adelante.
Por esta razón, se necesita un mejor algoritmo de control de congestión que es resistente a las pérdidas de ACK.
En este trabajo, proponen
TCP Santa Cruz, que es una nueva implementación de implementable TCP.
TCP Santa Cruz detecta no sólo las etapas iniciales de la congestión, pero también puede identificar la dirección de la congestión, es decir, se determina si la congestión se está desarrollando en el camino hacia delante y después hacia adelante aísla el rendimiento de eventos tales como la congestión en el camino inverso.
La dirección de la congestión se determina calculando el retraso relativo de que un paquete de experiencias con respecto a otro; este retraso relativo es la base de nuestro algoritmo de control de congestión.
TCP Santa Cruz proporciona una estrategia de recuperación de errores mejor que Reno y Tahoe hacen al proporcionar un mecanismo para llevar a cabo estimaciones RTT para cada paquete transmitido, incluyendo retransmisiones.
1. TCP Santa Cruz - Descripción del protocolo
TCP Santa Cruz proporciona una mejora a través de TCP Reno en dos áreas principales: el control de la congestión y la recuperación de errores.
El algoritmo de control de congestión TCP introducida en Santa Cruz determina cuando existe congestión o está desarrollando en la ruta de datos hacia adelante - una condición que no puede ser detectada por una estimación del tiempo de ida y vuelta.
Este tipo de monitoreo permite la detección de los estados incipientes de congestión, lo que permite la ventana de congestión para aumentar o disminuir en respuesta a señales de alerta temprana.
Además, TCP Santa Cruz utiliza cálculos retardo relativo para aislar el rendimiento hacia adelante de cualquier congestión que pueda estar presente a lo largo de la ruta inversa.
Los métodos de recuperación de errores introducidos en TCP Santa Cruz realizan oportunas retransmisiones de paquetes perdidos, eliminar las retransmisiones innecesarias para los paquetes recibidos correctamente cuando se producen pérdidas múltiples dentro de una ventana de datos, y proporcionan estimaciones RTT durante períodos de congestión y de la distribución (es decir, eliminar la necesidad de algoritmo de Karn).
1.1. Control de la congestión
a) La eliminación de ambigüedad RTT utilizando retardos relativos
Mediciones de tiempo de ida y vuelta por sí solos no son suficientes para determinar si existe congestión a lo largo de la ruta de datos.
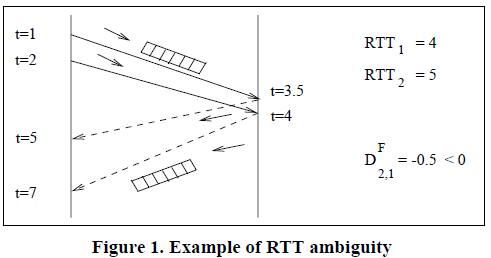
La figura 1 muestra un ejemplo de la ambigüedad que tienen lugar cuando se consideran únicamente las mediciones de RTT.
La congestión es indicada por una cola a lo largo de la trayectoria de transmisión.
El ejemplo muestra la transmisión de dos paquetes de datos y los ACKs que regresan desde el receptor.
La verdadera causa del aumento de RTT para el segundo paquete es la congestión a lo largo del camino de retorno, no la ruta de datos.
Nuestro protocolo resuelve esta ambigüedad mediante la introducción de la noción de la demora relativa.
Demora relativa es el aumento y disminución de la demora que los paquetes de experiencia con respecto a la otra cuando se propagan a través de la red.
Estas medidas son la base de nuestro algoritmo de control de congestión.
b) Algoritmo de control de congestión
En cualquier momento durante una conexión, las colas de la red (y específicamente la cola de cuello de botella) están en uno de tres estados: incrementan en tamaño, disminuyendo de tamaño, o el mantenimiento de su estado actual.
El diagrama de estados de la Figura 4 muestra cómo el cálculo del retardo relativo hacia adelante permite la determinación del cambio en el estado de la cola.
El objetivo en el TCP Santa Cruz es para permitir que las colas de la red (específicamente la cola de cuello de botella) para crecer a un tamaño deseado, el algoritmo específico para lograr este objetivo se describe a continuación.
Los valores de retardo relativos positivos y negativos representan cola adicional o menos en la red, respectivamente.
El algoritmo de control de congestión de TCP Santa Cruz opera mediante la suma de los retardos relativos desde el comienzo de una sesión, y a continuación, la actualización de las mediciones a intervalos discretos, con cada intervalo igual a la cantidad de tiempo para transmitir una ventana completa de datos y recibir los ACKs correspondientes .
En otras palabras, el algoritmo intenta mantener la condición siguiente:
Donde
nti es el número total de paquetes en cola en el cuello de botella a la hora de
ti, Nop es el punto de trabajo (el número deseado de paquetes, por sesión, para ser puesto en cola en el cuello de botella);
MWi-1 es la cantidad adicional de hacer cola durante una presentación la ventana anterior
Wi-1, y
nt1 = MW0.
1.2. Recuperación de Errores
a) Mejora de la estimación de RTT
TCP Santa Cruz ofrece una mejor estimación de RTT sobre los enfoques tradicionales TCP midiendo el tiempo de ida y vuelta (RTT) de todos los segmentos de transmisión para el cual se recibe un ACK, incluyendo retransmisiones.
Esto elimina la necesidad de que el algoritmo de Karn (en el que no se hacen mediciones de RTT para las retransmisiones) y las estrategias de temporizador backoff (en la que el valor de tiempo de espera se duplicó prácticamente después de cada tiempo de espera y de la distribución).
Para lograr esto, TCP Santa Cruz requiere que cada paquete ACK de retorno para indicar el paquete exacto que causó el ACK que se generan y el remitente debe tener una marca de tiempo para cada paquete transmitido o retransmitido.
Los paquetes se pueden identificar de forma única por especificando un número de secuencia y un número de copias retransmisión.
b) Ventana ACK
Para ayudar en la identificación y la recuperación de paquetes perdidos, el receptor TCP en Santa Cruz devuelve una ventana ACK al remitente para indicar cualquier agujero en la corriente secuencial recibido.
En el caso de múltiples pérdidas por ventana, la ventana TCP ACK permite-SC para retransmitir todos los paquetes perdidos sin tener que esperar por un tiempo de espera de TCP.
La ventana ACK es similar a los vectores de bits utilizadas en los protocolos anteriores, tales como NETBLT y TCP-SACK.
A diferencia de TCP SACK, el enfoque de este documento proporciona un nuevo mecanismo por el que el receptor es capaz de informar sobre el estado de todos los paquetes en la transmisión actual.
La ventana ACK se mantiene como un vector en el que cada bit representa la recepción de un número especificado de bytes más allá de la ACK acumulativo.
El receptor determina una granularidad óptima para los bits en el vector e indica este valor al remitente a través de un campo de un byte en la cabecera.
Esto ayuda a evitar la retransmisión innecesaria de paquetes recibidos correctamente después de un tiempo de espera cuando la sesión entra en arranque lento.
c) Política de retransmisión
La estrategia de retransmisión es motivada por pruebas como los informes de seguimiento de Internet por Lin y Kung, que muestran que el 85% de los tiempos de espera de TCP se debe a la "no-disparo".
"No-disparo" se produce cuando un paquete es retransmitido por el remitente sin intentos anteriores, es decir, cuando tres ACKs duplicados no llegan a la remitente y por lo tanto mecanismo de retransmisión rápida de TCP nunca ocurre.
En este caso, no hay retransmisiones pueden ocurrir hasta que hay un tiempo de espera en la fuente.
Por lo tanto, se necesita un mecanismo para recuperar rápidamente las pérdidas sin que sea necesario esperar tres ACKs duplicados desde el receptor.
Dado que TCP Santa Cruz cuenta con un presupuesto mucho más ajustado del tiempo RTT por paquete y que el TCP Santa Cruz remitente recibe información precisa sobre cada paquete recibido correctamente (a través de la ventana ACK), TCP Santa Cruz puede determinar cuando un paquete se ha caído sin esperando algoritmo de retransmisión rápida del TCP.
TCP Santa Cruz puede retransmitir y recuperar rápidamente un paquete perdido una vez que cualquier ACK sea transmitido posteriormente y sea cumpla una restricción de tiempo.
1.3 Implementación propuesta
TCP Santa Cruz se puede implementar como una opción de TCP que contiene los campos representados en la Tabla 1.
La opción TCP Santa Cruz puede variar en tamaño de 11 a 40 bytes,
2. Resultados de rendimiento
Se muestran los resultados de rendimiento para una configuración básica con una sola fuente y un enlace cuello de botella, y luego una sola fuente de tráfico cruzado en el camino de retorno, y, finalmente, el rendimiento a través de enlaces asimétricos.
Se midio el rendimiento de TCP Santa Cruz a través de simulaciones que utilizan la red "ns" simulador
El simulador contiene implementaciones de TCP Reno y TCP Vegas.
TCP Santa Cruz se llevó a cabo mediante la modificación del código fuente TCP Reno existente para incluir los nuevos regímenes de recuperación de errores y evitar la congestión.
2.1 Con guración Básica Cuello de botella
Nuestro primer experimento muestra el rendimiento del protocolo en una red simple, representado en la Figura 7, que consiste en una fuente TCP enviando paquetes de datos 1 Kbyte a un receptor a través de dos enrutadores intermedios conectados por un enlace de cuello de botella de 1,5 Mbps.
El BWDP de esta configuración es igual a 16.3Kbytes, por lo tanto, con el fin de acomodar una ventana completa de los datos, los routers se establecen para mantener los paquetes 17.
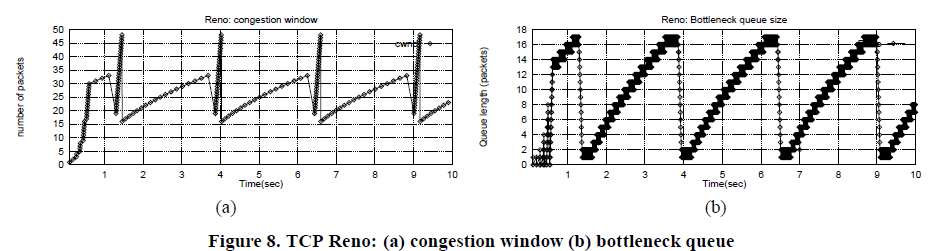
Las figuras 8 (a) y (b) muestran el crecimiento de ventana de congestión de TCP Reno y la acumulación de cola en el enlace de cuello de botella.
Los routers empiezan a caer los paquetes una vez que la cola está llena, con el tiempo Reno da cuenta de la pérdida, retransmisiones y reduce la ventana de congestión a la mitad.
Esto produce oscilaciones sube y baja, tanto en el tamaño de la ventana y de la longitud de la cola cuello de botella.
En contraste, las Figuras 9 (a) y (b) muestran la evolución de la ventana de congestión del remitente y la acumulación de cola en el cuello de botella para TCP Santa Cruz.
Estas cifras demuestran la fortaleza principal de TCP Santa Cruz: la adaptación del algoritmo de control de congestión para transmitir en el ancho de banda de la conexión sin congestionar la red y sin desbordamiento de las colas de cuello de botella.
La Figura 9 (b) muestra la longitud de la cola en el enlace de cuello de botella para TCP Santa Cruz alcanza un valor de estado estacionario entre 1 y 2 paquetes.
El algoritmo mantiene este valor de estado estacionario durante la duración de la conexión.
Conclusión
Se presento TCP Santa Cruz, que implementa un nuevo enfoque para el control de congestión de extremo a extremo y fiabilidad, y que puede ser implementado como una opción TCP.
TCP Santa Cruz hace uso de una marca de tiempo sencilla devuelto desde el receptor para estimar el nivel de formación de colas en el enlace de cuello de botella de una conexión.
El protocolo aísla con éxito el rendimiento hacia adelante de la conexión de eventos en el enlace inverso teniendo en cuenta los cambios en el retardo a lo largo de sólo el enlace directo.
El protocolo proporciona rápida y eficiente de recuperación de errores mediante la identificación de las pérdidas a través de una ventana ACK sin esperar tres ACKs duplicados.
Una estimación del RTT para cada paquete transmitido permite que el protocolo para recuperarse de retransmisiones perdidos sin el uso de estrategias de temporizador-backoff, eliminando la necesidad de algoritmo de Karn.
Los resultados de simulación muestran que TCP Santa Cruz proporciona un alto rendimiento y bajo retardo de extremo a extremo y la varianza del retardo a través de redes con un simple enlace cuello de botella, las redes con la congestión en el camino de retorno de la conexión, y redes que exhiben camino
asimetría.
Hemos demostrado que el TCP Santa Cruz elimina las oscilaciones en la ventana de congestión, pero todavía mantiene una alta utilización de enlace.
Referencias
[1] H. Balakrishnan, S. Seshan, and R. Katz. Improving reliable transport and handoff performance in cellular wireless networks. ACM Wireless Networks, Dec. 1995.
[2] L. Brakmo, S. O’Malley, and L. Peterson. TCP Vegas: New techniques for congestion detection and avoidance. In Proc. SIGCOMM’94, pages –, London, UK, Aug./Sept. 1994. ACM.
[3] L. Brakmo and L. Peterson. TCP Vegas: End-to-end congestion avoidance on a global internet. In IEEE Journal of Selected Areas in Communication, October, 1995.
[4] D. Clark, M. Lambert, and L. Zhang. NETBLT: A high throughput transfer protocol. In Proc. SIGCOMM, pages 353–59, Stowe, Vermont, Aug. 1987. ACM.
[5] K. Fall and S. Floyd. Simulation-based comparisons of tahoe,reno, and SACK TCP. In Computer Communication Review, volume 26 No. 3, pages 5 – 21, July, 1996.
[6] S. Floyd and V. Jacobson. Random Early Detection gateways for congestion avoidance. IEEE/ACM Transactions on Networking, 4(1):397–413, Aug 1993.
[7] R. Jacobson, R. Braden, and D. Borman. Rfc 1323 TCP extensions for high performance. Technical report, May 1992. Technical Report 1323.
[8] V. Jacobson and S. Floyd. TCP and explicit congestion notification. In Computer Communication Review, volume 24 No. 5, pages 8 – 23, October, 1994.
[9] P. Karn and C. Partridge. Improving round-trip time estimates in reliable transport protocols. In Computer Communication Review, volume 17 No. 5, pages 2 – 7, August 1987.
[10] S. Keshav. Packet-pair flow control. http://www.cs.cornell.edu/skeshav/papers.html.
[11] T. Lakshman, U. Madhow, and B. Suter. Window-based error recovery and flow control with a slow acknowledgement channel: a study of TCP/IP performance. In Proceedings IEEE INFOCOM ’97, number 3, pages 1199–209, Apr 1997.
[12] D. Lin and H. Kung. TCP fast recovery strategies: Analysis and improvements. In Proceedings IEEE INFOCOM ’98, Apr. 1998.
[13] L.Kalampoukas, A. Varma, and K. Ramakrishnan. Explicit window adaptation: a method to enhance TCP performance. In Proceedings IEEE INFOCOM ’98, pages 242 – 251, Apr. 1998.
[14] M. Mathis and J. Mahdavi. Forward acknowledgment: Refining TCP congestion control. In Proc. SIGCOMM’96, pages 1–11, Stanford, California, Sept. 1996.
[15] M. Mathis, J. Mahdavi, S. Floyd, and A. Romanow. TCP selective acknowledgment options. Technical report, Oct. 1996. RFC 2018.
[16] S. McCanne and S. Floyd. ns-lbnl network simulator. http://wwwnrg.ee.lbl.gov/ns/.
[17] C. Parsa and J. Garcia-Luna-Aceves. Improving TCP performance over wireless networks at the link layer. ACM Mobile Networks and Applications Journal, 1999. to appear.
[18] N. Samaraweera and G. Fairhurst. Explicit loss indication and accurate RTO estimation for TCP error recovery using satellite links. In IEE Proceedings - Communications, volume 144 No. 1, pages 47 – 53, Feb., 1997.
[19] W. R. Stevens. TCP/IP Illustrated, Volume 1. Addison-Wesley, 1996.
[20] J. Waldby, U. Madhow, and T. Lakshman. Total acknowledgements: a robust feedback mechanism for end-to-end congestion control. In Sigmetrics ’98 Performance Evaluation Review, volume 26, 1998.
[21] Z. Wang and J. Crowcroft. Eliminating periodic packet losses in the 4.3-Tahoe BSD TCP congestion control algorithm. In Computer Communication Review, volume 22 No. 2, pages 9 – 16, April, 1992.
[22] Z. Wang and J. Crowcroft. A new congestion control scheme: Slow start and search (Tri-S). In Computer Communication Review, volume 21 No. 1, pages 32 – 43, Jan., 1991.
Referencias de documento