Tema: Mobile Agent Middleware for Sensor Networks: An Application Case Study
Autores: Chien-Liang Fok, Gruia-Catalin Roman, and Chenyang Lu
Washington University in Saint Louis
1.- Introducción:
Las redes de sensores inalámbricos (siglas en ingles: WSN) consisten en pequeños sensores arraigados en el entorno.
Algunos ejemplos donde se aplica seria en la supervisión del hábitat, vigilancia, atención médica y en monitorear alguna estructura.
Estas aplicaciones tienen intervalos largos de implementación por el gran número de nodos, y su exposición al medio físico, y eso da lugar a una alta probabilidad de que muchos de ellos se desactivan.
Las WSN deben hacer frente a entornos altamente dinámicos, por ejemplo: mientras que una red de seguimiento de incendios este desplegado en un bosque, puede permanecer inactivo la mayor parte del tiempo, si un ocurre un incendio forestal y se extiende, debe de provocar rápidamente numerosas actividades en la red, entonces las aplicaciones de WSN tienen que ser flexibles y adaptables.
Las aplicaciones WSN son difíciles de desarrollar y desplegar, por ejemplo: una plataforma WSN se compone de MICA2 y TinyOS del sistema operativo, TinyOS es un sistema operativo basado en eventos, con una curva de aprendizaje alta, por lo tanto, las aplicaciones de TinyOS sólo pueden ser ligeramente ajustados, cambiando los parámetros definidos antes del despliegue.
En este tipos de casos, los Middlewares promete mejorar la flexibilidad de las aplicaciones WSN.
Excluyendo al proyecto Agilla, otros middlewares incluyen a XNP, Diluvio, Mat'e, SensorWare, Impala y los mensajes inteligentes.
Para hacer frente a las limitaciones de los middleware más arriba, se desarrollo "Agilla", un agente de middleware móvil para redes inalámbricas con sensores.
Agilla se basa en Mat'e, pero a diferencia de Mat'e, que divide una aplicación en cápsulas que se inundan a través de una red, Agilla permite a los usuarios instalar aplicaciones mediante la inyección de agentes móviles en una red de sensores.
Se implemento Agilla en un modulo MICA2 Mote y en el sistema operativo TinyOS.
En este artículo se presenta un estudio de caso de Agilla, utilizando una aplicación de seguimiento de incendios.
En esta aplicación, los agentes móviles se despliegan para formar y mantener dinámicamente un perímetro alrededor de un fuego ya que se propaga a través de una red.
En este artículo hacen tres contribuciones principales:
- En primer lugar, muestran cómo el middleware de agente móvil se puede utilizar para facilitar el desarrollo y el despliegue de una aplicación no trivial.
- En segundo lugar, se presentan resultados sobre el rendimiento a nivel de aplicación, demuestran la fiabilidad y la eficiencia de los agentes móviles.
- Y finalmente, en tercer lugar se proporcionan nuevos conocimientos con lecciones para técnicas de programación en agentes móviles para redes inalámbricas de sensores.
Y a continuación los temas del documento.
2.- Agilla Overview
Como se habia mencionado antes en el documento, las aplicaciones Agilla consisten en agentes móviles que pueden moverse y clonarse a sí mismos con realización a tareas específicas de la aplicación.
Agilla proporciona instrucciones de alto nivel que permiten a los agentes internos que lleven a cabo tareas complejas.
La arquitectura del agente móvil se muestra en la Figura 1.

Los agentes móviles utilizan una arquitectura de pila, ya que permite la mayoría de las instrucciones por ser de un solo byte.
El modelo Agilla se muestra en la Figura 2.

Cada nodo es compatible con un máximo de cuatro agentes, Agilla maneja automáticamente el cambio de contexto que permite a los agentes que se ejecutan simultáneamente e independientemente.
Agilla proporciona dos componentes que facilitan la coordinación entre los agentes: un espacio como tupla, y una lista conocida, Ambos se mantienen en cada nodo del middleware.
Para evitar el "sondeo", Agilla aumenta el espacio de tuplas con reacciones, que permiten a un agente para reaccionar a la presencia de una tupla que coincide con una plantilla determinada.
Se debe de tener en cuenta que Agilla no admite un espacio de tuplas global que se extiende a través de múltiples nodos, debido principalmente a las limitaciones de ancho de banda y la energía, en cambio, soporta espacios de tuplas locales en cada nodo mantiene un espacio de tuplas distintas y separadas.
Agilla también mantiene una lista de conocimiento en cada nodo, esta lista contiene la localización de todos los vecinos de un salto, también implementa su propio gestor de memoria dinámica para obtener instrucciones de agente y los espacios de tuplas.
3.- Aplicacion para monitorear el fuego.
La aplicación para monitorear el fuego se muestra en la Figura 4.

Un fuego se enciende en una región que estará dentro de la red de sensores, y a medida que el fuego se extiende, los agentes que estarán alrededor de él, se clonan en repetidas ocasiones para crear un perímetro, y una vez que se forma el perímetro, notifican al departamento de bomberos.
Al realizar el caso de estudio, se centraron en los agentes para monitorear.
Ellos moldearon el fuego con insertar tuplas donde contuvieran la cadena "estrella" en los nodos que informaban que se estaba "quemando", y el agente podía utilizar las operaciones de las tuplas remotas (por ejemplo, rrdp o rrdpg) para detectar los incendios.
Se utilizan dos tipos de agentes contra incendios para el modelado de fuego: estáticos y dinámicos, los agentes contra incendios estáticos simplemente insertan una tupla incendio en el espacio de tuplas locales.
El código se muestra en la Figura 5.

Los agentes estáticos se utilizan para crear los incendios de diferentes formas para el agente de seguimiento y así formar un perímetro alrededor del incendio.
El agente extintor dinámico funciona mediante la inserción de una tupla a su llegada, y luego haciendo parpadear el LED rojo un cierto número de veces.
Ahora, si el agente perseguidor del fuego descubre y forma un perímetro alrededor del fuego, muere si el nodo captura el fuego en ese perímetro, esto se realiza mediante el registro de una reacción que mata el agente cuando se inserta una tupla de fuego en el espacio de las tuplas locales.
El código que registra esta reacción se muestra en la Figura 6.

El ciclo de vida de un agente rastreador o perseguidor se muestra en la Figura 7.

El ciclo anterior muestra el como funciona comprobando repetidamente si alguno de sus vecinos están en llamas, si no hay ninguno, se realiza un movimiento débil para un vecino aleatorio y repite el proceso, y si un vecino está en llamas, entra en modo de seguimiento.
4.- Indicadores de Rendimiento
En este apartado, para evaluar su agente de seguimiento de incendios, probaron su rendimiento en una WSN con un modulo wirelles MICA2 Mote en
una cuadrícula de 5 x 5 (el modulo sirve como estación base por separado).
Mediante la disposición del modulo, fueron capaces de calcular la ubicación del nodo (x, y) en función de
su dirección.
Para crear una red multi-hop en el espacio limitado de su laboratorio, modificaron la pila de red TinyOS para filtrar todos
los mensajes, excepto los de los vecinos horizontales, verticales y diagonales sobre la base de la topología de la red.
Los resultados reflejaron los escenarios en los peores de los casos, debido a un aumento de la
probabilidad de colisiones inalámbricas.
Se realizaron dos tipos de pruebas: el primero, utiliza agentes contra incendios estáticos para
determinar la velocidad del perímetro, y el segundo, utilizaron los agentes contra incendios dinámicos para determinar qué tan bien los agentes Tracker
puede ajustar el perímetro cuando el fuego se propaga.
Para las pruebas de fuego con agentes estáticos, se inicia el WSN mediante la inyección de agentes contra incendios estáticos en ciertos
nodos para generar incendios de diversas formas y tamaños, un agente de seguimiento de incendios se inyecta en un nodo
al lado del fuego, al inyectar el agente de seguimiento junto al fuego, se
aísla la fase de descubrimiento de la fase de seguimiento.
Se hicieron pruebas en varios incendios diferentes, como se
muestra en la Figura 8.
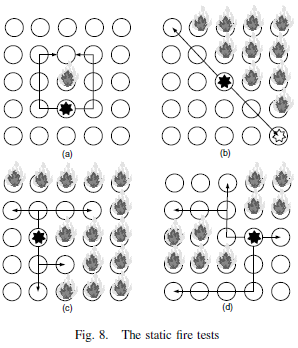
En la imagen se muestra cuando en el nodo se inyecta el agente detector y está marcado con una estrella de color negro, las flechas indican que el detector debe clonarse a sí mismo
para formar el perímetro.
Para realizar una captura del progreso al momento de formarse el perímetro, se utilizo una videocámara digital, y los resultados se muestran en la Figura 9.

En la imagen se puede observar que en la mayoría de los casos se forma el perímetro
dentro de 3 segundos.
En el escenario que llevó más tiempo es la escena A, y se debe a que su
configuración contenían áreas que impedían la propagación de agentes múltiples en
paralelo.
Los resultados que se muestran en la Figura 9, muestran
claramente cómo el punto inicial de seguimiento de fuego tiene un impacto
significativo en la velocidad a la que se forma el perímetro.
Para evaluar la capacidad del detector para mantener un
perímetro en un incendio, se inyectan cuatro agentes de
seguimiento de incendios en la red con una estrella
negro en la Figura 10, y luego se inyecta un agente de fuego dinámico en el nodo
(5,5).

Se llevaron a cabo dos pruebas: una con un agente de fuego lento y otro con fuero rápido, y se utilizó la cámara de vídeo digital para grabar cada
ejecución de las pruebas de fuego dinámico
Los resultados se muestran en la Figura 11.

En la imagen se muestra que el rastreador de fuego hace un buen trabajo al mantener un perímetro alrededor del fuego lento, pero tiene
dificultades con el fuego rápido.
En el experimento rápido, el agente de fuego
se extiende rápidamente.
La razón por la que ambos convergen al 100% se debe porque el
fuego se propaga, y la red se convierte en el tiempo saturado de un agente en
cada nodo.
5.- Lecciones aprendidas
Aquí, en este apartado muestran un pequeño resumen sobre las lecciones aprendidas durante todo el proyecto y en que se batallo y que fue lo mejor.
Se debe de tener una buena elección entre el uso de operaciones con migración
fuerte y débile, ya que tiene un impacto significativo en la complejidad y la
eficiencia del código.
Definitivamente el código fuente del agente se dividió en dos módulos
para reflejar los dos modos de funcionamiento, por ejemplo: la detección de
incendios y el seguimiento de incendios.
Se encontraron problemas
con respecto al tamaño del agente, al ser demasiado grande para caber dentro de las
limitaciones de memoria en el modulo MICA2 Mote.
Después de optimizar el agente en los dos
módulos, se percataron que el modo del agente podría inferir en base a que si
habían nodos vecinos en el fuego, eso permitió combinar los dos bloques de código para la reducción del tamaño de la agencia.
También notaron que el conjunto de instrucciones
puede reducir significativamente el tamaño del código.
Se agregaron dos instrucciones en el caso de estudio, fueron rrdpg y surrondings, rrdpg determina la dirección de todos
los vecinos, sin ella, cada vecino tendría que ser consultada de forma
individual.
A diferencia de otras instrucciones, rrdpg almacena los
resultados en la pila, ya que a menudo se utilizan en numerosas ocasiones.
La arquitectura de Agilla, permite a los
usuarios añadir y eliminar las instrucciones off-line, y cuando se compila y se instala, no se pueden agregar nuevas instrucciones.
Y finalmente notaron que la programación en un
lenguaje ensamblador es una tarea extremadamente tediosa y propenso a tener muchos errores.
A lo largo de todo el trabajo realizado, se demostró que Agilla se
puede utilizar para implementar aplicaciones complejas en redes de sensores
inalámbricas.
También se demostró cómo las aplicaciones múltiples
pueden compartir simultáneamente una red.
Se presento un caso de estudio de cómo los agentes móviles
se pueden utilizar para programar un WSN para el seguimiento de fuego.
Se demostró que los agentes móviles y su comunicación basada en tuplas son factibles, y estas abstracciones se pueden utilizar para
aumentar la flexibilidad de la red.
También se demostró que los agentes del perseguidor
de fuego pueden mantener un perímetro alrededor de un fuego dinámico, ya que se
propaga a través de una red.
Con la experiencia al desarrollar esta aplicación, se llevó a la adición de varias instrucciones, lo que permite a Agilla proporcionar una mejor base para desarrollar rápidamente aplicaciones flexibles
para redes inalámbricas de sensores.
Critica:
Durante todo el proceso del proyecto, debido al tiempo en que a pasado desde que se realizo, utilizaron herramientas algo obsoletas, ahora se podrían adquirir las mismas herramientas pero de mejores versiones y con nuevas funcionalidades.
También se podrían mejorar los algoritmos utilizados en la red de nodos, ya que como se mostró en algunas ocasiones se mostró que hubo fallas.
Y por ultimo, utilizaron lenguaje ensamblador es demaciado complicado, tedioso, consume tiempo, y todo por que es algo dificil, es mejor utilizar lenguajes de alto nivel, ya que se evitarian demaciados problemas
Referencia:
- Mobile Agent Middleware for Sensor Networks: An Application Case Study, Chien-Liang Fok, Gruia-Catalin Roman, and Chenyang Lu, Washington University in Saint Louis [PDF], paginas: 382 - 387.
Publicado en: Information Processing in Sensor Networks, 2005. IPSN 2005. Fourth International Symposium on.
Tipo de producto: Publicación de Conferencia.
Disponible en: http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=1440953&url=http%3A%2F%2Fieeexplore.ieee.org%2Fstamp%2Fstamp.jsp%3Ftp%26arnumber%3D1440953
Fecha de acceso: 27/05/2013